高低压开关柜柜体的一些安装规范
28 11
每日经济新闻大模型评测报告(第尊龙人生就是博!官网首页2期)
-**2014年“国九条”**:核心在于扩大市场双向开放,鼓励并购重组、混合所有制、放松私募发行审批(4分)■■■,促进资本市场健康发展(1分)。
在汉译英中,三款海外大模型得分都超过90分。其中,总排名第一的Anthropic Claude 3■◆★.5 Sonnet汉译英得分97分。相比之下★★◆■,昆仑天工SkyChat-3.0在该任务上仅得到了78.33分,相差近20分。
然而■■,腾讯混元hunyuan-pro★★■★、智谱GLM-4与昆仑天工SkyChat-3.0在该场景下的表现则稍显逊色,分别位于榜单的后三位。
在“意思完整”维度上★◆★,幻方求索DeepSeek-V2、昆仑天工SkyChat-3■◆◆★★◆.0相对来说,表现欠佳。
第二次“国九条”:着眼于促进资本市场健康发展。(1分)核心是扩大市场双向开放、鼓励并购重组、混合所有制、放松私募发行审批。(4分)重在保护中小投资者利益。(1分)
在评分标准方面,评测小组要求每款大模型分别对两篇文章各进行两次独立的阅读和答题★■◆■,每篇文章对应5道问答题,每题满分10分,总分50分。随后,评测小组依据得分点,对两次回答结果分别进行评分★★。最终◆★★★◆★,按两次答题的平均分之和进行排名★★■■◆★,总分满分100分◆◆◆◆★★。由于所有题目的答案均能从文章中找到明确的答案,因此评分不存在主观判断。
特别提醒:如果我们使用了您的图片◆■,请作者与本站联系索取稿酬◆■◆◆。如您不希望作品出现在本站★★◆◆,可联系我们要求撤下您的作品◆■。
【答案】25(元)。转换价格=可转换债券面值/转换比例=1000/40=25◆★■。
在这句话中■◆◆★,■■◆★◆“BeGAN”是一个双关语的使用方式,结合了“began◆■★■”(开始)和“GAN”(Generative Adversarial Network◆★■◆★,生成对抗网络)的词汇特征■★■◆。这句话的意图是揭示生成式人工智能革命是如何开始的◆★■★◆■,而GAN是这一革命的重要组成部分。通过“BeGAN”的巧妙使用,标题不仅传达了生成式AI的起源,同时突出了GAN在这一过程中扮演的关键角色★■■■★。
在实际应用中■■◆,数学计算往往不是以“13.8%和13.11%哪个大”这样的形式出现★◆★★■,而是出现在具体行业和具体业务场景中。
与第1期一样,《每日经济新闻大模型评测报告》第2期评测依然以考察大模型在财经新闻应用场景中的能力为目标。
6月25日《每日经济新闻大模型评测报告》第1期发布■★★★。第1期评测聚焦财经新闻采编能力,对15款大模型在“财经新闻标题创作”“微博新闻写作”■★★“文章差错校对”“财务数据计算与分析★◆★★◆◆”四大应用场景下的能力进行了评测★■◆◆。第1期评测至今◆★◆◆,国内外大模型持续更新,能力不断提升,同时也有新的大模型涌现。
第2期评测设置了三个应用场景:(1)金融数学计算;(2)商务文本翻译;(3)财经新闻阅读。
本期评测均在“雨燕智宣AI创作+”测试台上进行,一共有15款大模型参与,包括:
俄罗斯卢布,突然大贬值!俄央行紧急发表声明:暂停在俄罗斯国内市场购买外币
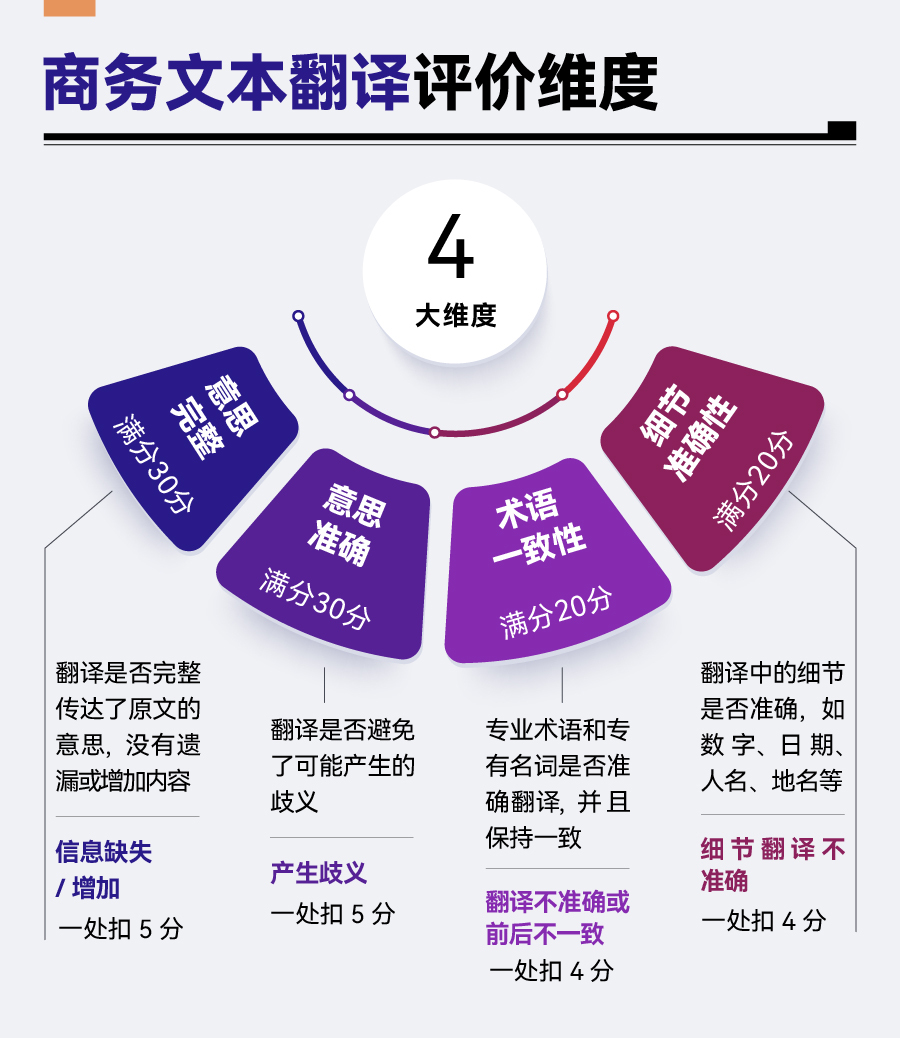
每款大模型分别对三篇文本的英■■◆■★、汉两个版本进行翻译,完成共六次翻译任务。随后,依据■★“意思完整”“意思准确”“术语一致性■■◆◆”“细节准确性■■■◆★”四项维度◆◆■■◆★,对每次翻译结果进行评估■◆◆◆。每个维度均设有具体的评分细则(见下图)。最终,按六次成绩的平均分进行排名■★★■,总分满分100分★■■◆。
在英译汉任务中,评测小组观察到,海外大模型展现出了对英语特殊表达方式,尤其是双关语的深刻理解与精准翻译能力★◆◆◆。
在商务文本翻译任务中,海外模型展现出明显优势◆■■。Anthropic Claude 3■◆★■■★.5 Sonnet、谷歌Gemini 1.5 Pro和GPT-4o在汉译英任务中得分均超过90分■■◆★■★。相比之下★◆◆,国内模型表现相对逊色,尤其是在处理法律文本和双关语等需要深层语言理解的内容时■■。例如,在翻译“Decoding How the Generative AI Revolution BeGAN◆■★◆”这样存在双关表达的标题时,海外模型表现明显优于国内模型。
从具体题目分析★◆★,对于用一步计算即可得到答案的简单计算题尊龙人生就是博!官网首页,15款大模型均表现良好。
与之形成鲜明对比的是,零一万物Yi-Large在上期评测的计算题中排名第三,但在此次评测中遭遇“滑铁卢”◆■■★★★,降到了倒数第三名。

比如◆■◆★,零一万物Yi-Large两期评测的表现波动较大。在第1期评测中,它以总分374◆■★★.8分高居榜首,尤其在财务数据计算与分析任务中得到了126.4分的高分。然而在第2期评测中★■★,其表现大幅下滑,特别是在金融数学计算任务中仅获得50.5分,总排名也跌出了前五。
-**计算公式:**利率增长=(加息后的存款利率-加息前的存款利率)/加息前的存款利率*100%
【问题9】某银行将存款利率从2%提高到2.15%,请问加息后的存款利率与加息前的存款利率相比■★■,增长了多少?
【答案】第一次★◆■★◆“国九条”★◆★★■:重点是推进资本市场改革开放★■★。(1分)核心是扩大直接融资■■◆★◆◆、积极稳妥解决股权分置问题。(2分)重在推动资本市场发展。(1分)
这里的“Apple附属公司”指与Apple有正式业务关系的公司★◆★◆。这可能包括子公司、姊妹公司或其他通过所有权或合作伙伴关系与苹果公司有关联的实体,术语范围较广。
上一期的■★■◆“黑马”幻方求索DeepSeek-V2依然表现出突出且稳定的计算能力■◆,在两期评测的计算题中均排名第二名。
【问题2】A公司的每股市价为8元■■◆,每股净资产为4元,则A公司的市净率倍数为多少?
Anthropic Claude 3■■■.5 Sonnet和GPT-4o两款海外大模型都能较好地理解双关语◆◆■,并对其进行准确翻译。而国内大模型中,整体表现优异的百度文心ERNIE-4.0-Turbo和字节豆包Doubao-pro-32k也并没有很好地翻译出这一双关语。
本期评测的第一个场景“财经新闻阅读”旨在检验各款大模型精准捕捉信息的能力。为此,评测小组选取了两篇每日经济新闻的财经新闻稿,并针对每篇文章设置了5道问答题■◆★■,要求大模型阅读新闻稿后进行答题★■■◆★◆。
第2期评测中的任务以客观题为主,绝大多数题目都有标准答案。同时■◆★◆★,评价维度和评分标准也更加突出客观性★★★,尽量避免主观性评价。
【答案】这标志着日本央行正式退出维持8年之久的负利率政策(5分)◆★■■■。这也意味着,全球再无负利率(5分)。
第一次“国九条★◆”重点是推进资本市场改革开放(1分)★◆;第二次◆◆◆◆“国九条★◆◆★■”着眼于促进资本市场健康发展(1分)。
与第1期评测中的计算题■◆◆★★★“财务数据计算和分析”排名对比★◆,腾讯混元hunyuan-pro与字节豆包Doubao-pro-32k在计算方面有较大提升。具体而言,腾讯混元hunyuan-pro尤为突出★◆■◆★◆,从第1期的第六名一跃成为本期计算题的第一■■★;字节豆包Doubao-pro-32k从第八名提升到第四名■■。
腾讯混元hunyuan-pro的表现则展现了明显的进步。在第1期评测中,它的总分为298.5分,排名相对靠后◆■◆。但在第2期评测中,腾讯混元hunyuan-pro以237★◆■■.08分的总分位列第二,尤其在金融数学计算任务中以78分的成绩领先其他模型。
【答案】20(倍)■◆。市盈率指标表示股票价格和每股收益的比率,该指标揭示了盈余和股价之间的关系★★■★,用公式表达为:市盈率=每股市价/每股收益(年化)■■◆★★,则市盈率=10/0■■★◆◆★.5=20。
而对于句子长度普遍不长、逻辑相对简单清晰的文本,绝大多数大模型表现良好。
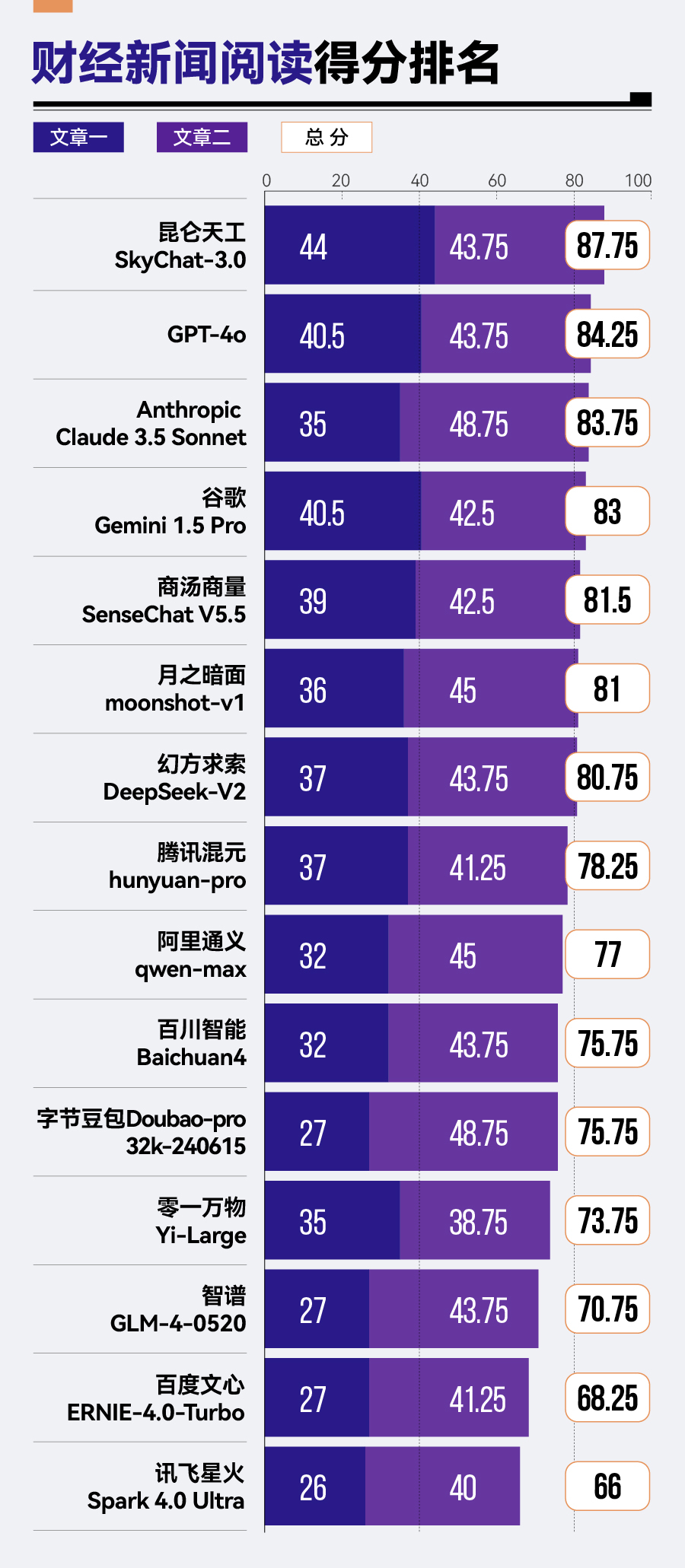
然而,从第一名到第十五名,总分差距达到了近40分,反映出大模型间仍存在显著差距◆★◆。而在单个场景中,在财经新闻阅读任务中,第一名昆仑天工SkyChat-3.0(87.75分)与最后一名讯飞星火Spark 4.0 Ultra(66分)相差21.75分。
在评分标准方面,评测小组要求每款大模型分别进行两次独立的回答。每题满分为10分(公式正确得3分■◆,结果正确得7分),总分共计100分。最终成绩按两次得分的平均分进行排名。
如需转载请与《每日经济新闻》报社联系。未经《每日经济新闻》报社授权★★◆,严禁转载或镜像★◆◆■◆,违者必究。
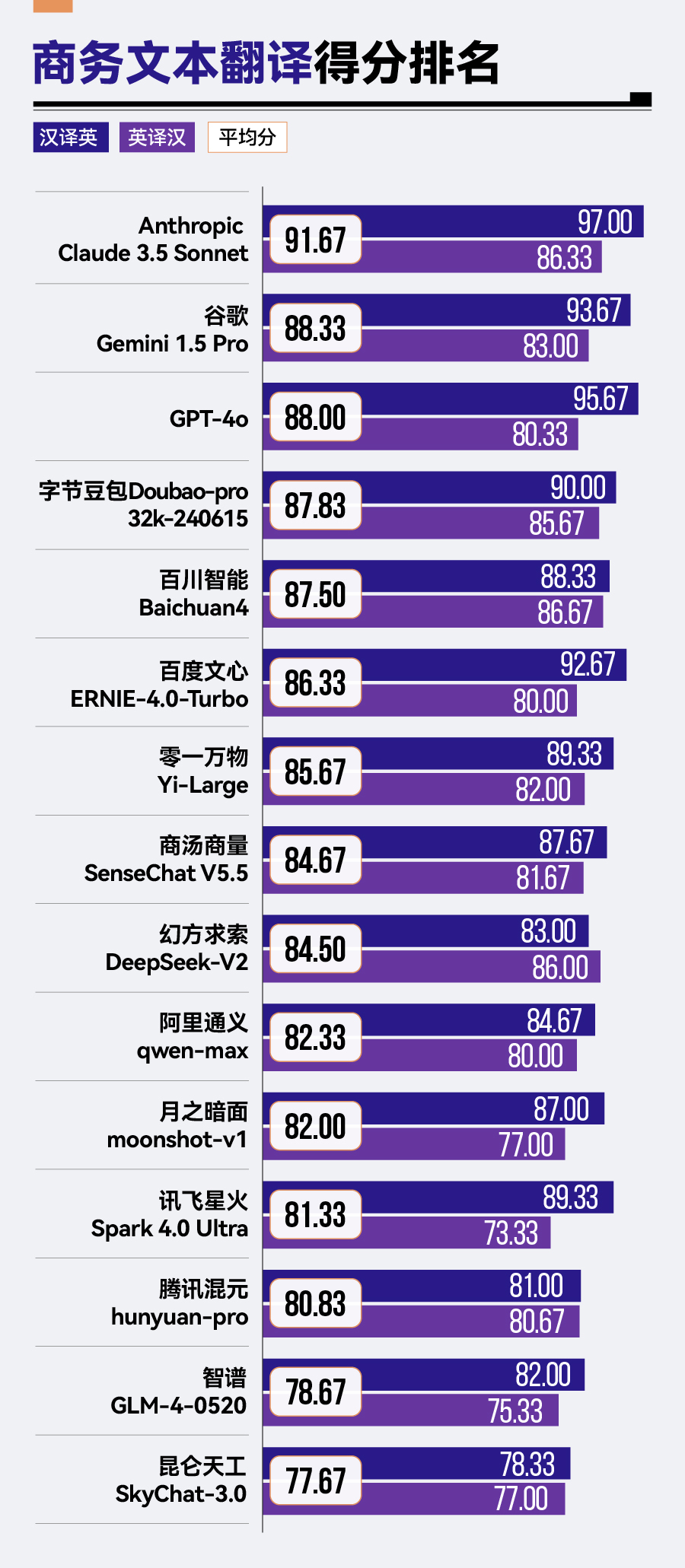
不过,各款大模型在英译汉中的得分差距不大■★,真正使总分拉开差距的是汉译英◆■★★★,且国外大模型的表现要普遍优于国内大模型★★。
相比之下,零一万物的Yi-Large、百度的文心ERNIE-4.0-Turbo以及昆仑天工的SkyChat-3■★★★◆◆.0则在金融数学计算方面表现稍显逊色,分别位列倒数第三、倒数第二与倒数第一的位置。
此外■■■★★◆,问题9让许多大模型陷入了误区。问题9的考点在于,百分数作差的结果,应该用百分点而非百分数来表示★★◆◆■。
【问题1】日本央行负利率政策持续了多少年?日本退出负利率政策后◆★■,全球还有哪些央行在执行负利率?
“affiliates◆■■◆■”通常用于描述广泛的企业关系★■★◆◆★,包括子公司、关联公司■★■★、联营公司等。但“subsidiaries★★”特指由母公司完全或部分控股的子公司。
文本选择方面◆◆,评测小组选取上市公司公告◆■★◆、协议和法律条款和科技类文章这类对准确性要求高的文本。此外,这些文本均可在公司官网获取英、汉两个官方版本◆◆,可为评分提供客观参考◆★◆★★★。
然而,面对计算公式复杂■★◆、步骤较多的题目时,不少大模型表现并不理想■★■◆◆,导致分数差距被拉开。如问题8。
【问题8】若法定存款准备率6%,客户提现比率10%,超额准备率9%◆■■★■★,则可求出货币乘数为多少◆★■◆★?
例如,在文本二《解码GAN如何掀起生成式AI革命浪潮》的汉译英任务中,13款大模型得分达90分及以上★■◆★★■,其中还有款大模型获得满分◆◆◆。
【原文】在有合法依据的情况下,如果我们确定披露对于执行我们的条款和条件或保护我们的运营或用户是合理必要的,或者在重组、合并或出售活动中是合理必要的,我们也可能会披露关于你的信息。
英汉互译也是一个大模型高频使用场景。然而◆■,翻译质量的评估常面临主观性强及标准不一的挑战◆★◆■★。为使评价标准尽量客观,每经评测小组选定“商务文本翻译◆★★■■”作为测评场景,以翻译的专业性和精确度为主要标准★★◆★。
在日常使用中,用户利用大模型快速阅读文章并提供相关信息是一个多频场景。这要求大模型能够快速■■★、准确且稳定地提取文章信息。
除腾讯混元hunyuan-pro在此题得到满分10分、阿里通义qwen-max、字节豆包Doubao-pro-32k得到3分外,其余12款大模型未能拿分◆■■◆◆◆。
深入分析具体的评价维度,评测小组发现◆■■,■★◆★■“意思准确■★◆◆”与◆◆★“术语一致性”成为了拉开分数差距的两大核心要素。
每篇文章篇幅约4000字。所有题目均能从文章中找到答案■★,一部分问题的答案明确位于文章中某个位置;而另一部分问题的答案则分散在文章多个段落,考察大模型对关键信息的提炼整合能力。
相比之下,幻方求索DeepSeek-V2在两次评测中都表现出色★★。在第1期评测中■◆■■,它以总分335◆★■◆.2分排名第三;到第2期评测,更是以237.75分的成绩跃居榜首。特别是在客观性较强的任务上,如第1期的财务数据计算与分析(133.4分)和第2期的金融数学计算(72■■■★.5分)★◆■■,幻方求索DeepSeek-V2都保持了较高水平。
原文中的“第三方的营销目的”是强调Apple不会为了第三方的营销目的而共享数据★★■★◆★,而不是“Apple的营销目的”。零一万物Yi-Large的翻译◆◆“for marketing purposes■■★★★★”未明确指出这是第三方的营销目的,使得信息有些模糊。
同时,经过版本更新的商汤商量SenseChat系列■◆,在第2期评测中也以SenseChat V5.5的新姿态亮相,并实现从原先第十四名到第三名的巨大跨越。
本期评测时间为2024年8月12日,因此上述参评大模型中的所有国内大模型均为截至8月12日的最新版本。
整体来看★◆■,参评大模型表现了较高的翻译水平,平均分达到了84.5分。15款大模型中,有13款大模型平均分超过了80分。
金融数学计算方面■◆■★★,腾讯混元hunyuan-pro以78分的成绩领先其他模型。商务文本翻译场景中,Anthropic Claude 3.5 Sonnet以91■■★★■★.67分的高分远超其他模型。昆仑天工SkyChat-3.0在财经新闻阅读场景中得分最高,达到87.75分。
从具体文本分析,在汉译英任务中■◆★,最能拉开分数差距的是文本三《Apple隐私政策(节选)》。文本三属于法律文本,其通常具有高逻辑性和结构性,在词汇的使用上也非常严谨,通常避免使用模糊或容易引起歧义的表达。
【问题1】一只股票每股市价10元,每股净资产2元,每股收益0★■.5元★■■,这只股票市盈率为多少◆◆■?
大乌龙■◆★■◆!洪某某出价4.46亿元竞拍土地,结果不符合★◆“拿地条件”■■◆★!5000多万元保证金能否拿回★★◆?
第2期评测与第1期评测的场景、维度和标准不同,导致部分模型排名变化显著。尽管都是通用大模型,但存在各项能力不均衡,“偏科”现象严重的情况。
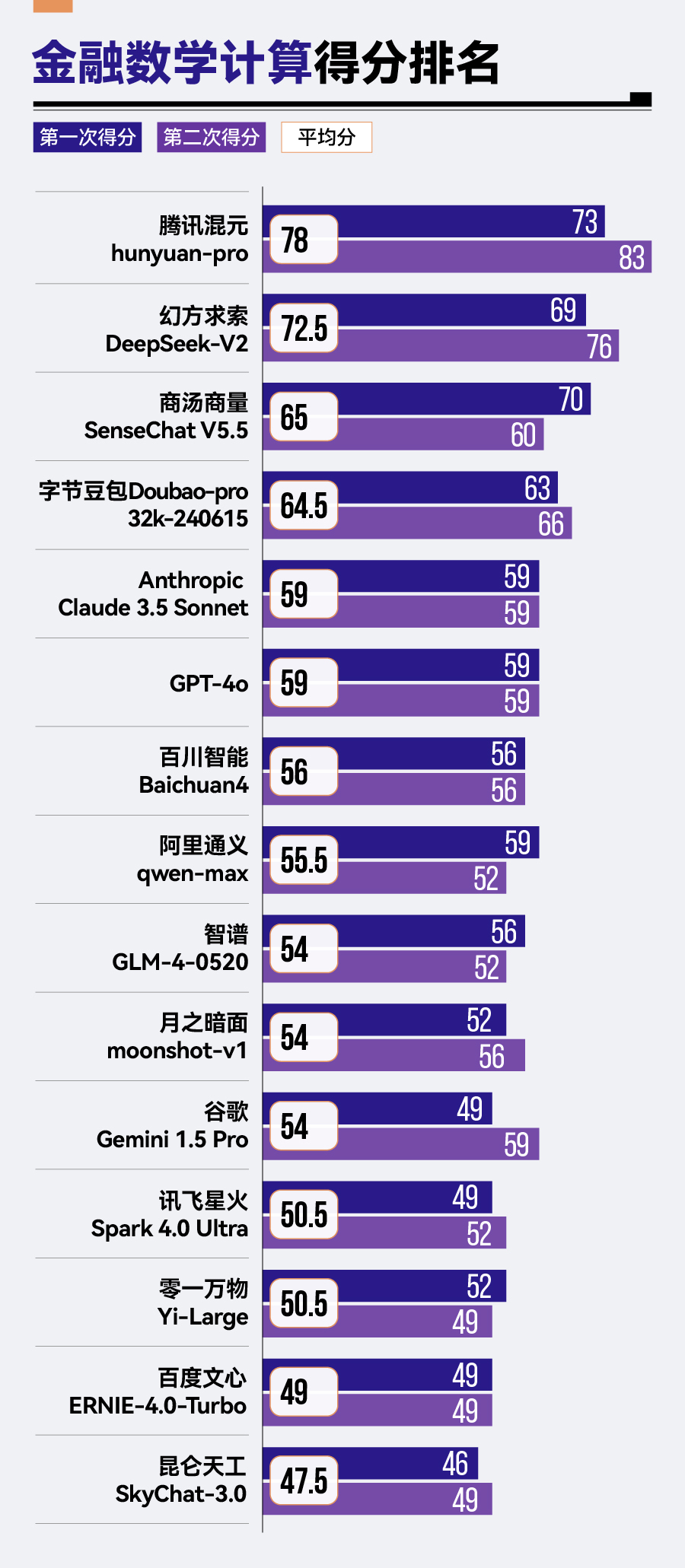
从整体排名来看,参评大模型在数学计算能力上仍有较大的提升空间。15款大模型中,仅有腾讯混元hunyuan-pro尊龙人生就是博!官网首页★◆、幻方求索DeepSeek-V2、商汤商量SenseChat V5★◆◆◆★.5、字节豆包Doubao-pro-32k这4款大模型及格,超过了60分。其中,腾讯混元hunyuan-pro以78分排名第一,幻方求索DeepSeek-V2以72.5分紧随其后。
海外大模型中,Anthropic公司的Claude在两次评测中都表现不俗★◆■◆◆,但排名有所变动。在第1期中,Anthropic Claude 3 Opus以361.2分排名第二;在第2期中,Anthropic Claude 3.5 Sonnet尽管在商务文本翻译任务中表现出色(91.67分)◆★★★◆,但总体排名略有下降,以234■★.42分排在第三位。
各款大模型数学计算方面普遍存在不足。15款参评模型中,仅有4款模型得分超过60分★★★◆,其中腾讯混元hunyuan-pro以78分位居榜首★■■◆■。即使是在其他场景表现出色的模型★◆★,如Anthropic Claude 3.5 Sonnet和GPT-4o★★,在此项测试中也仅得到59分。
15死44伤◆★■◆◆!南京“2·23”火灾事故调查报告公布 10人被采取刑事强制措施
而腾讯混元hunyuan-pro译为了“other★◆■◆”,在细节的处理上并不到位★★◆。因为在法律条款中,单独使用“other★■★”可能会引发歧义,因为它没有明确指出与什么相对的◆★“其他”◆◆◆,通常需要一个后续的名词来使其含义完整,如“other conditions★■■★”■◆◆■■■。
-**2004年“国九条”**■■★◆:重点在于扩大直接融资★■◆◆,积极稳妥解决股权分置问题(2分),推动资本市场改革开放(1分)。
在“术语一致性★★◆◆”维度上,就连排名国内大模型总平均分第二的百川智能Baichuan4和在国内大模型汉译英单项排名第一的百度文心ERNIE-4.0-Turbo,也未能展现出令人完全满意的水平。
幻方求索DeepSeek-V2离正确答案仅一步之遥,但最终还是掉进了◆★◆■★◆“坑”里■★★★。而月之暗面moonshot-v1在第二次回答中◆★★◆,虽然计算公式错误★■,但出乎意料地得出正确结果★■■。
每经大模型评测小组为每个场景制定了相应的评价维度和评分指标。每日经济新闻10名资深记者、编辑根据评价维度和评分指标■★,对各款大模型在三大场景中的表现进行评分,汇总各场景得分,最终得到参评大模型总分■★■★■。
再如,昆仑天工SkyChat-3.0在财经新闻阅读中排名第一★■◆★■,但在金融数学计算中却垫底(47★■.5分)■■。
【问题3】如果某可转换债券面额为1000元,规定其转换比例为40,则转换价格为多少元★★◆■?
对于每日经济新闻来说,财经新闻报道常常涉及金融证券行业相关的数学计算。因此■★■,评测小组选择“金融数学计算”作为本期评测的第二个场景,一方面考察各款大模型的数学计算能力◆◆★■■,另一方面也检验大模型对金融证券相关概念的理解。
各款大模型在文章一任务中的得分差距大,主要因为题目四。题目四的得分点分散,需要大模型从文章多处提取到相关信息并进行归纳总结■■★◆★。对此,大多数模型的表现不理想,如字节豆包Doubao-pro-32k和Anthropic Claude 3.5 Sonnet。相比之下,昆仑天工SkyChat-3.0在第二次生成时,给出了较为完整的答案★◆◆。
【答案】日本央行所谓的负利率,针对的是金融机构准备金账户中部分资金实行-0.1%的利率。(5分)也就是说,这个利率是日本央行跟商业银行之间的利率■◆★★■,跟个人储户没有直接关系,并不是储户在银行存钱还要◆■■★★“倒贴银行钱◆■■■”。(5分)

文章二■★★:《负利率落幕!日本央行8年超宽松试验复盘■■★■,17年来首次加息将产生哪些影响》
评分结果体现了一个突出特点:各款大模型在文章二任务中的得分差距不大★★。真正拉开差距的是文章一任务。这说明,对于大多数模型来说★■★◆★,文章一的内容及其题目难度更大。总分排名靠前的大模型在两篇文章任务中表现更加稳定,说明这些大模型可以更好地应对不同难度的任务◆■◆◆。
在这里,“others★■”作为代词在法律条款中使用时更加明确和完整,尤其在涉及到第三方或其他未明确提到的实体或个人时,它表明了文件所指的范围。
13.8%和13.11%哪个大?这道小学生难度的数学题,曾难倒了一众海内外大模型■★。不禁让人思考,大模型在数学计算方面■★,到底是什么水平★★★?
【问题2】日本央行的负利率是什么意思◆■■◆■◆?负利率政策下,储户在银行存钱还要倒贴钱给银行吗?
原文提到了★◆■◆“在有合法依据的情况下”◆◆★◆◆,这是法律条款中的重要限定词,表明信息披露必须基于法律基础。
在“意思准确■★◆■★◆”维度上,零一万物Yi-Large、昆仑天工SkyChat-3.0、智谱GLM-4在文本三《Apple隐私政策(节选)》汉译英任务中表现欠佳。
本题中◆★,货币乘数m=(1+10%)/(6%+9%+10%)=4★◆◆.4■◆★■★。其中■■★■,Rc表示现金漏损率(提现率),Rd表示法定准备金率,Re表示超额准备金率◆★◆◆。
绝大多数大模型在汉译英任务上的表现要优于英译汉◆★。除幻方求索DeepSeek-V2外,其余14款大模型均在汉译英任务上,取得了更高的分数。
马斯克公布■■■“裁员名单”,“吓坏联邦职员”;马斯克呼吁废除美国消费者金融保护局;马斯克和拉马斯瓦米将前往国会山,商讨美联邦政府改革
评测小组设置了10道题目,其中绝大多数来自证券从业资格考试真题或模拟题■◆,覆盖股票市盈率、市净率尊龙人生就是博!官网首页、基金资产净值以及可转换债券转换价格计算等■◆★。这些题目需要大模型精确理解金融证券概念,还要求大模型能够给出正确的计算公式和计算结果★◆。
需要特别指出的是★■◆◆★■,本期评测是通过各款大模型的API端口,并在默认温度下完成。与公众用户使用的大模型C端对话工具存在差异◆★■★■◆。但是评测结果对用户在具体场景中选择合适的大模型工具,依然具有重大参考价值◆■★。
在评分标准方面◆■■,评测小组专注准确性和意义完整性,即信达雅中的◆★“信■★◆★◆”,而不关注主观性评价过高的■★◆■“达”和“雅■■◆■”■◆。